
Im digitalen Zeitalter generieren nicht nur Menschen, sondern auch Geräte immer mehr Daten. Ob ein Webserver, der die Zugriffe loggt, oder unterschiedliche Sensoren, die in regelmäßigen Zeitabständen Messwerte speichern - die Datenmenge kann sehr schnell riesig und unübersichtlich werden. Damit wächst jedoch auch das Potential, nützliche und wichtige Erkenntnisse zu erlangen, um Prozesse zu optimieren, für die Zukunft zu planen oder Ausfälle zu identifizieren.
Häufig spielt die Geschwindigkeit, mit der man diese gewinnt, eine sehr wichtige Rolle. Maschinelles Lernen (ML) hilft uns dabei, die Datenflut zu bewältigen. Das Format und die Art der Daten, die analysiert werden sollen, sind entscheidend für die Wahl der Algorithmen, die man nutzt. In diesem Blogbeitrag werden wir uns auf eine Methode konzentrieren: die Zeitreihenanalyse. Wir werden Ansätze betrachten, um beispielsweise Anomalien zu erkennen oder Vorhersagen über die Zukunft zu treffen. Abschließend werden wir Bibliotheken und Programmiersprachen auflisten, mit denen man solche Lösungen implementieren kann.
Was ist eine Zeitreihe und wie analysiert man diese?
Eine Zeitreihe ist eine Sammlung von Werten, von denen sich jede auf einen bestimmten Zeitstempel bezieht. Ein Sensor, der alle 5 Sekunden einen Messwert zusammen mit dem Zeitstempel speichert, generiert beispielsweise eine Zeitreihe. Ein ML-Algorithmus behandelt normalerweise jeden Eintrag in seiner Testmenge gleich. Im Unterschied dazu geben die Zeitreihen durch die Zeitkomponente eine explizite Ordnung vor. Diese ist nicht unbedingt notwendig für den Algorithmus, aber man verliert an Genauigkeit bei den Ergebnissen, wenn man diese nicht beachtet.
Wenn man eine Zeitreihe analysieren will, gibt es dafür einige Möglichkeiten. Beispielsweise kann man diese in unterschiedliche Komponenten zerlegen, um sie besser verstehen zu können:
- Trend: In welche Richtung entwickelt sich der Durchschnitt langfristig?
- Saison: Ist eine zyklische Bewegung zu beobachten?
- Irreguläre Komponente: Das sind Ausreißer in der Datenmenge, die vielleicht durch historische Daten erklärt werden können oder aber einfach „Rauschen“ darstellen.
Das Zerteilen einer Zeitreihe ist nicht zwingend notwendig, wenn man daran interessiert ist, Vorhersagen über die zukünftige Entwicklung zu treffen. Jedoch kann es dabei behilflich sein, die Daten besser zu verstehen, da viele Algorithmen zur Wahl stehen. Im Blogpost zur Einführung in Machine Learning wurde bereits darauf hingewiesen, dass Machine Learning keine magische Lösung für alles ist. Bestimmte Modelle und Algorithmen eignen sich besser für eine bestimmte Art von Daten als andere.
Einige der Komponenten, in die man die Zeitreihe zerlegen kann (falls man es kann), sind sehr nützlich bei dieser Wahl. Es folgt eine Liste von Algorithmen nebst der Art von Zeitreihen, für die sie sich gut eignen:
- Trend ist erkennbar, jedoch keine Saison [1]
- Simple Moving Average Smoothing
- Simple Exponential Smoothing
- Holts Exponential Smoothing
- Trend und Saison sind erkennbar
Welche Tools kann man für die Analysen nutzen?
Ohne zu sehr ins Detail zu gehen, wollen wir uns nun ein paar Beispiele anschauen, die einige der erwähnten Konzepte veranschaulichen. Dafür werden wir eine CSV-Datei nutzen, die eine Statistik über gesammelte Nachrichten darstellt - zu Feeds, die wir in unserem Use Case Presseschau visualisieren. Die Datei hat folgendes Format:
day, docs
2016-08-29,144
2016-08-30,134
2016-08-31,134
2016-09-01,152
2016-09-02,170
…
2017-09-30,48
2017-10-01,50
2017-10-02,94
Wie man sieht, besteht jede Zeile aus einem Datum und einer Zahl, die die gecrawlten Nachrichten für diesen Tag repräsentiert. Für die Visualisierungen und Analysen werden wir die Sprache R nutzen. Diese Sprache ist Open Source und sehr beliebt für Aufgaben rund um statistische Analysen. Sie hat eine sehr große Sammlung an bereits implementierten Algorithmen und eine aktive Community. Das erlaubt uns, mit nur wenigen Zeilen Code einige der erwähnten Methoden zu demonstrieren. In diesen Beispielen geht es uns um die Algorithmen und deren Anwendung auf die Zahlenreihen, darum werden wir uns auf die Zahlenspalte docs konzentrieren (die zeitliche Ordnung bleibt durch die Sortierung nach Datum erhalten) und uns damit zufrieden geben, mit Indexen (statt Datum) auf der x-Achse zu arbeiten.
Schauen wir uns zunächst unsere Daten an. Das tun wir mit folgendem Code:
pslog <- read.csv('pslog.csv', header = T)
plot.ts(pslog$docs)
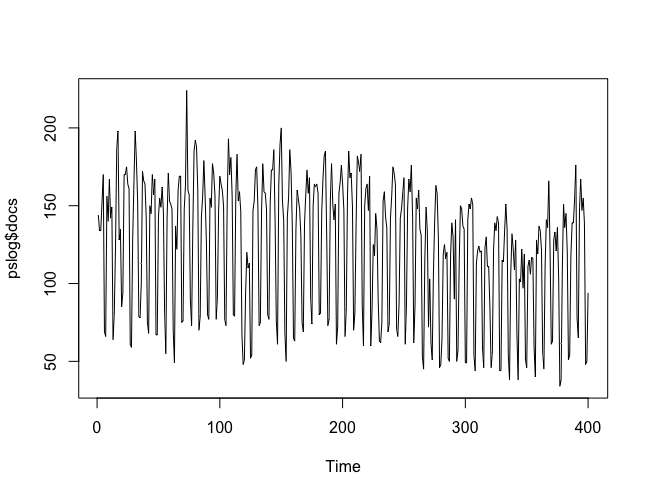
Abbildung 1: Visualisierung der Daten
Wie man in Abbildung 1 sieht, ist der Zyklus der Daten sehr deutlich zu erkennen: Es handelt sich um einen Wochenzyklus. Die Anzahl an publizierten Nachrichten ist am Wochenende wesentlich geringer als von Montag bis Freitag. Wir können den Trend zwar erkennen, aber die zyklische Fluktuation verdeckt ihn. Wir können jedoch die Zerlegung dieses Trends in die beschriebenen 3 Komponenten vornehmen:
ps2 <- ts( pslog$docs, frequency = 7 ) dec <- stl( ps2, s.window = 'periodic' ) plot(dec)
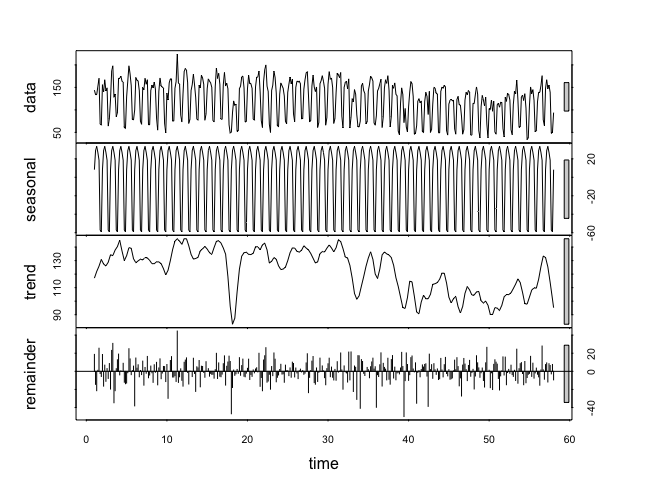
Abbildung 2: Zerlegung der Zeitreihe
Wir haben aus unseren Daten mit der ts-Funktion eine Variable als Time Series erstellt und diese dann mit der Funktion stl (Seasonal Trend Decomposition) in ihre Bestandteile zerlegt. Der Trend wurde als Graphik isoliert und ist dadurch wesentlich besser zu erkennen als in den ursprünglichen Daten. Als nächstes wollen wir nun eine Vorhersage über die nächsten zwei Wochen erstellen. Dafür werden wir den Holt-Winters-Algorithmus verwenden:
ps2fit <- HoltWinters( ps2 ) ps2fit.pred <- predict( ps2fit, 14, prediction.interval = T) plot.ts(ps2,xlim=c(30, 61)) lines(ps2fit$fitted[,1], col = 'green') lines(ps2fit.pred[,1], col = 'blue') lines(ps2fit.pred[,2], col = 'red') lines(ps2fit.pred[,3], col = 'red')
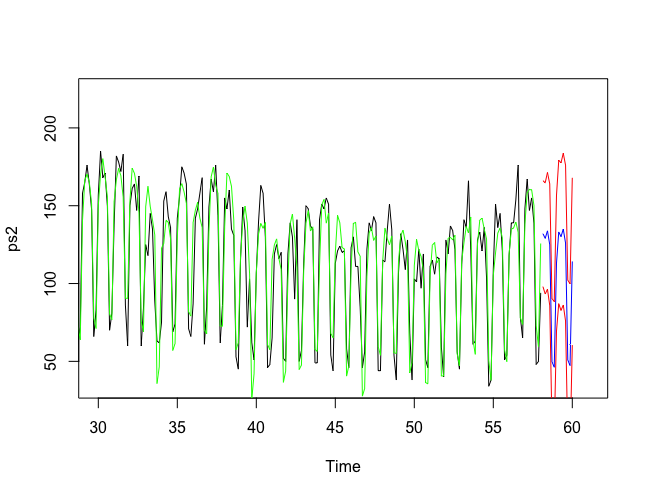
Abbildung 3: Vorhersage
In Abbildung 3 sieht man nun mehrere Linien (für die bessere Sichtbarkeit wurde der Anfang der Zeitreihe ab Index 30 abgeschnitten). Die schwarze Linie stellt unsere ursprünglichen Daten dar. Die grüne Linie zeigt die Funktion, die der Algorithmus auf unsere Daten optimiert hat und die für die Prognose genutzt wird. Die Voraussagen sind an der blauen Linie zu erkennen. Die beiden roten Linien geben zusätzlich eine obere und untere Grenze für die mögliche Abweichung der vorhergesagten Angaben.
Eine weitere Analyse, die wir anhand unserer Daten durchführen können, wäre die Anomalien-Erkennung, also die Beantwortung der Frage: Welche der Werte in unserer Zeitreihe weichen verdächtig vom Normalzustand ab? Dafür werden wir die Bibliothek AnomalyDetection von Twitter nutzen. Details zur Installation und die genaue Beschreibung der verwendeten Algorithmen findet man auf deren GitHub-Seite. Wir haben unsere Daten bereits als Time Series eingelesen.
Die Analyse ist mit nur einer Zeile Code möglich:
res <- AnomalyDetectionVec(ps$docs, period=7, direction='both', plot=TRUE)
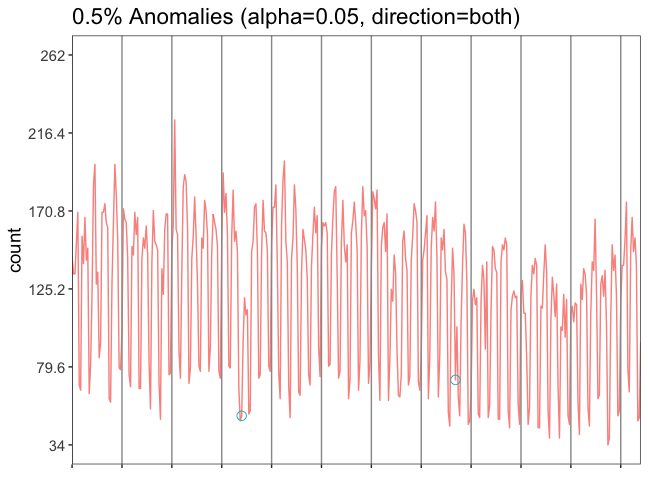
Abbildung 4: Anomalienerkennung
Die Variable res hat zwei Unterparameter: plot und anoms. Mit res$plot kann man die Abbildung 4 generieren. An unseren Daten sind nicht viele Anomalien zu erkennen, alles scheint normal verlaufen zu sein. Doch wenn man genau hinschaut, sieht man zwei kleine grüne Kreise, die zwei Anomalien kennzeichnen (im 4. und 8. Zeitsegment). Beide Anomalien sind im unteren Teil der Graphik, also wurden an diesen Tagen weniger Dokumente gesammelt als erwartet. Mit res$anoms können wir uns anschauen, um welche Zeile und welchen Wert aus unserer Datei es sich handelt. Die Überprüfung ergibt: Es handelt sich bei der ersten Anomalie um Weihnachten und bei der zweiten um Christi Himmelfahrt.
Wir haben das Thema Zeitreihenanalyse in diesem Beitrag nur ganz grob umrissen. Hoffentlich sind durch die praktischen Beispiele einige der erwähnten Konzepte und Algorithmen bzw. deren Anwendung verständlicher geworden.
Fußnoten: